EDIT 25. Mai 2021: Das „Server-Side Tagging“ von Google Tag Manager entwickelt sich weiter und das Umgehen von Adblockern wird immer einfacher. Ich habe dem Artikel den Abschnitt „Den Adblockern einen Schritt voraus“ hinzugefügt.
Google Tag Manager, das Trojanische Pferd für Marketingteams
Google Tag Manager ist ein TMS (Tag-Management-System): Es ermöglicht Marketingteams, Tracker auf einer Website oder in einer Anwendung hinzuzufügen, ohne den Umweg über Entwickler nehmen zu müssen. Über eine Weboberfläche können diese Teams Folgendes festlegen:
- Welche Tracker ausgelöst werden (Analytics, A/B-Tests, Attribution usw.).
- Unter welchen Bedingungen sie ausgelöst werden (Seitenkategorien, Nutzereigenschaften usw.).
- Welche Daten an diese Drittanbieter-Tools übermittelt werden (Nutzereigenschaften, Navigationsdaten, auf der Seite vorhandene Variablen usw.).
Es ist nicht das einzige (man kann zum Beispiel Segment, das französische TagCommander oder Matomo Tag Manager nennen), aber Google Tag Manager ist ultradominant:
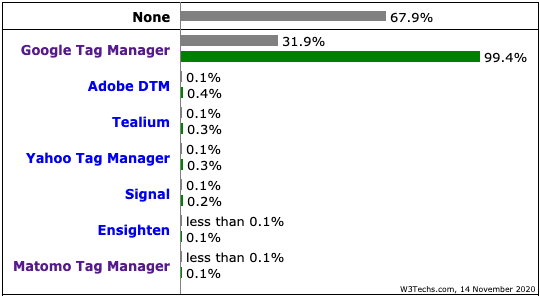
Google Tag Manager ist laut W3Techs auf 31,9 % der zehn Millionen meistbesuchten Alexa-Websites vertreten, vor allem aber hat Google Tag Manager einen Marktanteil von 99,4 % bei den TMS (!)
Wie konnte sich Google erneut durchsetzen? Wie bei Google Analytics ist die Standardversion von Google Tag Manager kostenlos (die marktüblichen Lösungen sind in der Regel kostenpflichtig), sehr gut in die anderen Google-Lösungen integriert und gut gemacht.
Tracker, die nicht mehr von Ihrem Browser aufgerufen werden
Im vergangenen August kündigte Google eine neue Version von Google Tag Manager an, genannt Server-Side Tagging. Hier ist ein Diagramm von Google, das erklärt, wie Google Tag Manager in der Client-Side-Tagging-Version (der „historischen“ Version) funktioniert:
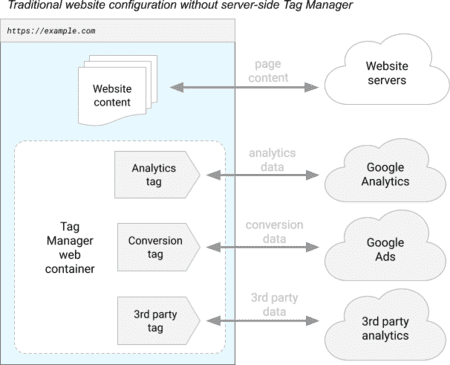
Google Tag Manager ermöglicht das Auslösen verschiedener Drittanbieter-Tracker (im Diagramm: Google Analytics, Google Ads und ein Analytics-Tool) direkt in Ihrem Browser.
In der neuen Server-Side-Version werden die Drittanbieter-Tracker nicht mehr über Ihren Browser ausgeführt, sondern über einen „Proxy“-Server, der im Diagramm unten „Server container“ genannt wird (und bei Google gehostet ist):
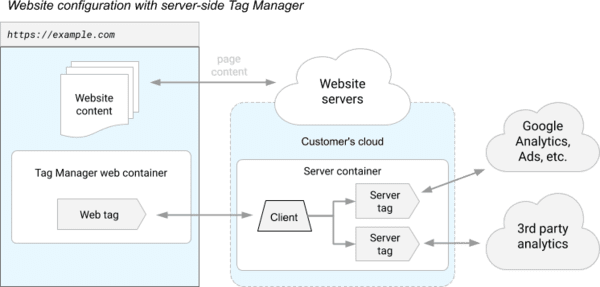
Die JavaScript-Bibliothek (im Diagramm „Tag Manager web container“ genannt) läuft weiterhin in Ihrem Browser, um Ihre Interaktionen und Ihre personenbezogenen Daten zu erfassen, die Ausführung der verschiedenen Drittanbieter-Tracker erfolgt jedoch serverseitig.
Beachten Sie, dass diese neue Version auch für Anwendungen und die Erfassung von „Offline“-Daten gilt (z. B. zur Übermittlung von Einkäufen im Geschäft):
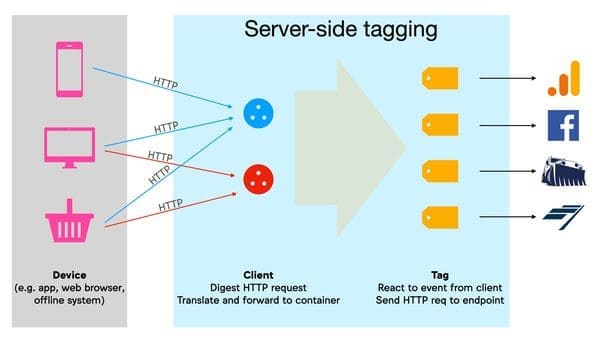
Diagramm aus Simo Ahavas Blog: Auf der Serverseite übersetzen die „Clients“ die empfangenen HTTP-Anfragen in „Events“; die „Tags“ reagieren auf diese Events, um „Hits“ an Drittanbieter-Marketingunternehmen zu senden.
Diese Logik, Drittanbieter-Tracker serverseitig auszulösen, verändert die Lage grundlegend. Simo Ahava hat die verschiedenen Auswirkungen in einem ausgezeichneten Artikel detailliert beschrieben. Ich werde meinerseits die Vorteile zusammenfassen und mich auf die Probleme für Ihre Privatsphäre konzentrieren (serverseitiges Arbeiten kann es ermöglichen, Ihre Entscheidungen zu umgehen und Ihre personenbezogenen Daten preiszugeben, ohne dabei aufzufallen).
Bessere Nutzererfahrung
Auf den meisten Websites ist die Anzahl der von Dritten geladenen JavaScript-Bibliotheken (für Analytics, Werbung, A/B-Tests usw.) beeindruckend. Das Laden und Ausführen dieser Bibliotheken ist häufig die Hauptursache für eine schlechte Nutzererfahrung: langsame Seiten und mangelnde Interaktivität.
Die Folgen für Websites mit schlechter Nutzererfahrung: weniger zufriedene Nutzer, die die Seite sofort verlassen oder nicht mehr zurückkehren.
Hier ist ein Beispiel mit Le Bon Coin, das eine unzählbare Menge an JavaScript-Bibliotheken aufruft:
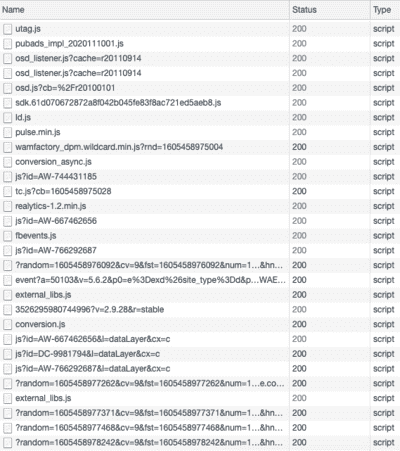
Ein kleiner Teil der auf der Startseite von Le Bon Coin aufgerufenen JavaScript-Skripte, das Ihre personenbezogenen Daten an zahlreiche Dritte weitergibt.
Im besten Fall installiert die Website nur eine einzige JavaScript-Bibliothek (da sich die Events zwischen Tools mit unterschiedlichen Zielen stark unterscheiden können, verwendet eine Website manchmal mehr als eine Bibliothek). Das kann die Bibliothek von Google Tag Manager sein, muss es aber nicht: Man kann eine eigene Bibliothek entwickeln oder andere Bibliotheken am Markt nutzen, etwa Snowplow, Matomo, AT Internet usw.
Anschließend ist diese Bibliothek dafür zuständig, die „Hits“ mit den bei Schlüsselinteraktionen erforderlichen Parametern zu senden. Danach muss der „Client“ des Server-Containers diese „Hits“ in Events übersetzen; diese werden von den „Tags“ gelesen, die „Hits“ an Drittanbieter-Marketingunternehmen senden. Beachten Sie, dass der „Client“ bereits in Google Tag Manager vorkonfiguriert ist, wenn die auf der Website installierte JavaScript-Bibliothek von Google bereitgestellt wird. Verwendet die Website eine andere Bibliothek, muss sie in Google Tag Manager einen eigenen „Client“ erstellen (Beispiel mit AT Internet), solange es noch keine vorkonfigurierten „Clients“ für die wichtigsten JavaScript-Tracking-Bibliotheken gibt.
Der Vorteil also: Auf der Website ist eine einzige JavaScript-Tracking-Bibliothek installiert, mit einem einzigen „Datenfluss“ vom Browser. Der Nutzer sollte den Unterschied bemerken.
Bessere Kontrolle über an Dritte übermittelte Daten
Mit einem serverseitigen „Proxy“ können Sie die an Dritte übertragenen Daten kontrollieren (was deutlich schwieriger ist, wenn die Tracker direkt vom Browser des Nutzers ausgeführt werden):
- Standardmäßig und anders als in der „clientseitigen“ Version werden die IP-Adresse und der User-Agent des Nutzers (Browsername, Version, Betriebssystem, Sprache usw.) nicht weitergegeben (was eine Identifizierung des Nutzers per „Fingerprinting“ verhindert). Der Publisher, der die Server-Side-Tagging-Version von Google Tag Manager nutzt, kann entscheiden, diese Informationen an Dritte zu übertragen, automatisch geschieht das aber nicht.
- Häufig werden personenbezogene Informationen über URL-Parameter an Dritte weitergegeben (lesen Sie zum Beispiel den Artikel „Google Tag Manager Server-Side — How To Manage Custom Vendor Tags“); Server-Side Tagging hilft, dies zu verhindern.
- Generell hat der Publisher die Kontrolle über die personenbezogenen Daten und Cookies, die sein „Proxy“ an Dritte sendet (lesen Sie die technische Dokumentation von Google; beachten Sie zum Beispiel die Methoden get_cookies und set_cookies). Er kann die Informationen also „bereinigen“ und nur das unbedingt Notwendige an Dritte senden.
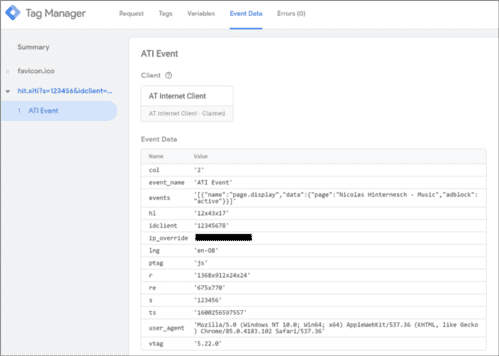
Beispiel für einen AT-Internet-Hit, der vom „Proxy“-Server „gesehen“ wird: Die Website kann entscheiden, die IP-Adresse und den User-Agent des Nutzers nicht an AT Internet zu übermitteln.
Eine sicherere Website
Das Einrichten einer Content-Security Policy (CSP) ermöglicht es einem Publisher, sich besser vor verschiedenen Arten von Bedrohungen zu schützen, darunter XSS-Angriffe (Cross-Site Scripting) und Content-Injections. Indem die Website ihren Webserver-Antworten einen Header hinzufügt, kann sie den Browsern mitteilen, welche Ressourcen (Skripte, CSS usw.) zulässig sind.
Hier ist ein von Google dokumentiertes CSP-Beispiel:
Content-Security-Policy: script-src 'self' https://apis.google.com.
Das heißt: Der Browser darf nur Skripte ausführen, die direkt von der aufgerufenen Website stammen ('self') oder von apis.google.com. Und so reagiert Ihr Browser, wenn anschließend ein bösartiges Skript versucht, von der aufgerufenen Website aus ausgeführt zu werden:
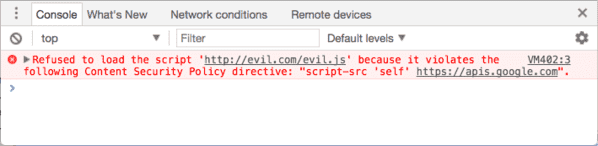
Das Skript evil.js wird weder auf der aufgerufenen Website noch auf apis.google.com gehostet: Seine Ausführung wird vom Browser blockiert.
Indem die Zahl der zur Ausführung von JavaScript-Code berechtigten Drittanbieter-Domains stark reduziert wird, wird die CSP robuster.
So sehr Server-Side Tagging Vorteile für Nutzer bietet, die der Marketingüberwachung zustimmen (Geschwindigkeit, Sicherheit), so sehr gefährdet es den Schutz von Nutzern, die nicht zustimmen.
Eine Umgehung des Browserschutzes
Der „Proxy“-Server wird in der Google-Cloud gehostet (App Engine-Instanz), aber Google empfiehlt, die App-Engine-Domain mit einer Subdomain der Website seiner Kunden zu verknüpfen (ohne die Gründe dafür zu erläutern):
Die Standardbereitstellung des Server-Side Tagging wird auf einer App-Engine-Domain gehostet. Wir empfehlen Ihnen, die Bereitstellung so zu ändern, dass stattdessen eine Subdomain Ihrer Website verwendet wird.
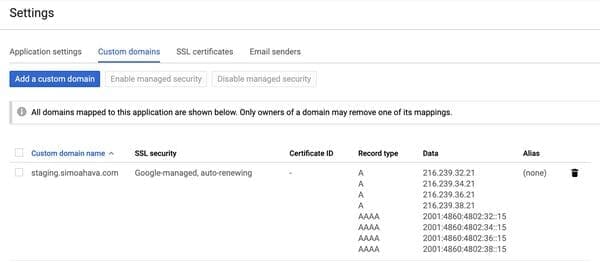
Die Verknüpfung zwischen der App-Engine-Domain und der Subdomain des Kunden, dokumentiert von Google.
Google empfiehlt keinen DNS-Eintrag vom Typ CNAME (Alias), sondern einen DNS-Eintrag vom Typ A oder AAAA, der direkt mit den IP-Adressen von Google App Engine verknüpft ist, das als Host fungiert. Der „Proxy“-Server wird daher von den Browsern als First-Party betrachtet, und die Konsequenzen sind erheblich.
Insbesondere sind die vom „Proxy“-Server gesetzten Cookies weder Drittanbieter-Cookies noch über JavaScript erstellte Cookies noch von einer CNAME-Domain gesetzte Cookies. Sie sind daher uneingeschränkt zugelassen:
- Safari beschränkt über die Intelligent Tracking Prevention (ITP) die Lebensdauer von in JavaScript erstellten Cookies auf 7 Tage (Beispiel: die von Google Analytics erstellten First-Party-Cookies). Dank des „Proxy“-Servers setzen sich Drittanbieter-Tracker nun über diese Einschränkung hinweg.
- Ebenfalls über die ITP beschränkt Safari nun die über eine CNAME-Domain gesetzten Cookies auf 7 Tage. Dank des „Proxy“-Servers sind Drittanbieter-Tracker von dieser Einschränkung nicht betroffen.
- Brave seinerseits blockiert CNAME-Anfragen an bekannte Tracker. Auch hier umgehen Drittanbieter-Tracker dank des „Proxy“-Servers diese Blockierung.
Eine Umgehung von Adblockern
Ihr Adblocker (uBlock Origin auf Firefox zum Beispiel), Ihr Inhaltsblocker (Firefox Focus oder AdGuard auf iOS zum Beispiel) oder Ihr DNS-Blocker (NextDNS zum Beispiel) funktioniert auf Ihrem Gerät. Dadurch können Tracker von Drittanbietern erkannt und blockiert werden, bevor Ihre persönlichen Daten preisgegeben werden.
Nichts davon gilt bei der Server-Side-Tagging-Version von Google Tag Manager: Die Lecks personenbezogener Daten laufen vom Proxyserver des Kunden (gehostet in der Google-Cloud) zu den Dritten. Sie haben daher keine Möglichkeit mehr, diese Lecks zu verhindern.
Sie könnten sich denken: Es genügt, den ersten Aufruf zu blockieren, also den Ihres Browsers an die JavaScript-Bibliothek, die für die Datenerfassung und die Kommunikation mit dem „Proxy“-Server zuständig ist. Nur kann diese JavaScript-Bibliothek durchaus von der eigenen Domain der Website ausgeliefert werden (und nicht etwa von einer Google-Domain). Zudem empfiehlt Google seinen Kunden bereits, ihre gtag.js-Skripte so zu ändern, dass sie die Domain des Proxyservers angeben. Schon durch diesen Eingriff wird die Blockierung über den Domainnamen wirkungslos.
Alle Tracking-Bibliotheken von Google (gtag.js, analytics.js, aber auch gtm.js, die „erweiterte“ Bibliothek von Google, die für Google Tag Manager zuständig ist) können auf einer eigenen Domain gehostet werden.
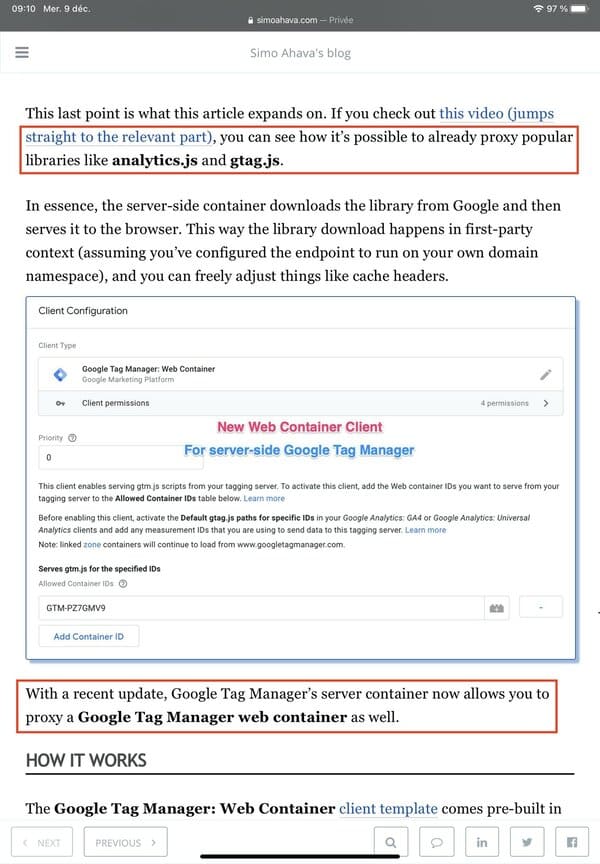
Via Simo Ahavas Blog.
Zwar sind gtag.js und gtm.js JavaScript-Bibliotheken, deren Namen den wichtigsten Adblockern bekannt sind, doch diese müssen andere Methoden finden, sobald der Name der JavaScript-Bibliothek geändert wurde oder Websites ihre eigenen Bibliotheken erstellt haben.

uBlock Origin, wirksam gegen CNAME-Cloaking auf Firefox, machtlos gegen Server-Side Tagging?
Den Adblockern einen Schritt voraus
Die JavaScript-Bibliothek von Google Tag Manager heißt gtm.js und wird mit der Container-ID aufgerufen: GTM-.... Ein Adblocker kann diese Namen daher leicht ins Visier nehmen und das Laden dieser Bibliothek blockieren. Eine Website könnte beschließen, eine eigene JavaScript-Bibliothek zu erstellen, aber das ist nicht so einfach.
Doch erneut dank Simo Ahava ist es nun einfach, einen anderen Namen für die JavaScript-Bibliothek gtm.js zu wählen und die Container-ID zu verbergen (man muss keine eigene JavaScript-Bibliothek mehr erstellen):
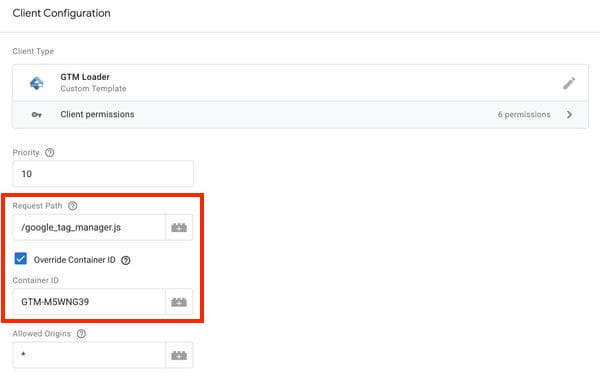
Via Simo Ahavas Blog: Mit Simos Vorlage „GTM Loader“ kann die Website die JavaScript-Bibliothek umbenennen („Request Path“) und die Container-ID verbergen („Override Container ID“ aktiviert, „Container ID“ leer).
Und selbst wenn die Adblocker den Google-Proxy ins Visier nehmen konnten, kann eine Website den Servercontainer nun an anderer Stelle hosten (auf Amazon AWS, Microsoft Azure, OVH... oder auf ihrer eigenen Infrastruktur). Das ist nicht ganz einfach, aber Google stellt das Docker-Image und die nötigen Schritte bereit.
So erläutert Simo Ahava das Vorgehen, um den Servercontainer auf Amazon AWS bereitzustellen, während Mark Edmondson detailliert beschreibt, wie man den Servercontainer auf Google Cloud Run bereitstellt (ein weiterer Dienst der Google Cloud Platform, der sich von Google App Engine unterscheidet).
Wie können Adblocker reagieren?
Das Thema ist nicht offensichtlich, hier sind einige Ideen, aber ich bin nicht sicher, ob sie umsetzbar sind:
- Diese „First-Party“-Aufrufe an den „Proxy“-Server automatisch anhand der gesendeten URL-Parameter erkennen. Nur ändern sich diese URL-Parameter von einer Website zur anderen, je nach verwendeter Bibliothek, aufgerufener Seite usw.
- Die JavaScript-Bibliothek erkennen, die für die Aufrufe an den „Proxy“-Server verantwortlich ist, um deren Ausführung zu blockieren. Wie wir gesehen haben, funktioniert diese Methode nicht, wenn die Website die Bibliothek von Google Tag Manager umbenennt oder eine eigene JavaScript-Bibliothek entwickelt.
- Die Proxys blockieren, auf die Gefahr hin, wesentliche Website-Funktionen mitzublockieren? Außerdem funktioniert diese Methode nicht, wenn die Website beschließt, den Servercontainer auf ihrer eigenen Infrastruktur zu hosten.
- Niemals JavaScript im Browser ausführen, zum Beispiel mit der NoScript-Erweiterung, radikal konfiguriert. Eine wirksame Option, nur dass dann viele Websites nicht mehr funktionieren.
Ihre personenbezogenen Daten in völliger Undurchsichtigkeit preisgeben
Auch wenn heutzutage viele Websites Ihre personenbezogenen Daten preisgeben, häufig ohne Ihre Zustimmung, ist es dennoch möglich, die Websites zu prüfen, den Verstoß gegen die Einwilligung nachzuweisen und die Datenlecks zu dokumentieren. Die CNIL könnte beispielsweise ihre Arbeit tun und Verstöße ahnden. Nichts davon gilt bei Server-Side Tagging: Eine Website kann nun ganz einfach:
- den Anschein einer Einwilligung erwecken, indem sie Sie auf ein Einwilligungsbanner antworten lässt.
- und gleichzeitig Ihre personenbezogenen Daten an mehrere Dritte weitergeben, ohne dass ein externer Prüfer dies bemerken kann (er sieht lediglich den „First-Party“-Aufruf an den „Proxy“-Server, ohne zu wissen, ob die personenbezogenen Daten dahinter verwendet, weitergegeben oder weiterverkauft werden).
Ihre Daten in der Google-Cloud
Standardmäßig protokolliert der „Proxy“-Server alle Anfragen, die er erhält:
Standardmäßig protokolliert App Engine Informationen zu jeder einzelnen Anfrage (z. B. Anfragepfad, Abfrageparameter usw.), die es erhält.
Die in diesen Anfragen enthaltenen personenbezogenen Daten sind jedoch nicht die einzigen Informationen, die an Google weitergegeben werden. Genau wie beim CNAME-Cloaking werden die mit der Domain der aufgerufenen Website verknüpften Cookies an die Subdomain des „Proxy“-Servers gesendet. Wenn Ihre Sitzungscookies also mit der Domain der Website verknüpft sind (und nicht mit einer separaten Subdomain), werden sie tatsächlich an die Google-Cloud gesendet.
Google erklärt, dass die in seiner Cloud gehosteten Daten dem Kunden gehören und nicht Google. Dennoch müssen Sie Google vertrauen.
Der Server-Side Tagging wird wahrscheinlich bald weit verbreitet sein
Zwar existierten Server-Side-Lösungen schon lange auf dem Markt, und es war bereits möglich, einen eigenen „Proxy“ zu entwickeln, doch die Einführung der Google-Lösung wird die Verbreitung von Server-Side Tagging wahrscheinlich enorm vorantreiben:
- Google Tag Manager ist auf einer beträchtlichen Anzahl von Websites präsent und äußerst dominant.
- Google präsentiert diese Version als Weiterentwicklung der TMS-Tools, die die Leistung und Sicherheit von Websites verbessert.
- Ein großes Argument für Marketer: Ihre personenbezogenen Daten an Facebook weiterzugeben.
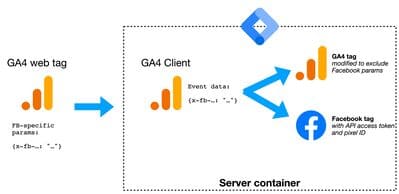
Ein Google-Analytics-Tag kann die Weitergabe Ihrer personenbezogenen Daten an Facebook verbergen — Kombo!
Auch wenn ein Google-Tag-Manager-Kunde die Client-Side-Version weiter verwenden kann, auch wenn die Server-Side-Version noch Grenzen hat (wenige Drittanbieter-Bibliotheken, einige Lösungen werden schwer zu unterstützen sein usw.), auch wenn das Erlernen der Lösung komplex ist und auch wenn sie oft kostenpflichtig ist (Google-App-Engine-Rechnung für den „Proxy“-Server), kann man also darauf wetten, dass Google-Tag-Manager-Kunden nach und nach auf diese Version migrieren werden.
Das Umgehen von Adblockern und anderen Browser-Schutzmaßnahmen ist ein Verkaufsargument
Wie wir gesehen haben, erklärt Google nicht, warum für seinen „Proxy“-Server eine Subdomain der Website angelegt werden soll:
Die Standardbereitstellung des Server-Side Tagging wird auf einer App-Engine-Domain gehostet. Wir empfehlen Ihnen, die Bereitstellung so zu ändern, dass stattdessen eine Subdomain Ihrer Website verwendet wird.
Es braucht das auch nicht: Die Umgehung von Browser-Schutzmaßnahmen und Adblockern wurde bereits in zahlreichen Veröffentlichungen als „Vorteil“ aufgeführt:
- „Server-side Tagging In Google Tag Manager“ von Simo Ahava: Der Artikel nennt als Vorteil, die Einschränkungen von Safari bei der Lebensdauer von JavaScript-Cookies umgehen zu können. Zu seiner Ehre will der Autor nicht näher darauf eingehen, dass Server-Side Tagging die Umgehung von Adblockern ermöglicht, und weist darauf hin, dass die Datenerhebung erst nach Einholung der Einwilligung erfolgen darf.
- „GTM Server Side – die natürliche Weiterentwicklung für Ihr Tagging?“ von Converteo. Der Artikel führt als Vorteile auf, Browser-Einschränkungen wie die von Safari und Firefox sowie Adblocker umgehen zu können.
- „Introduction to Google Tag Manager Server-side Tagging“ aus dem Blog Analytics Mania. Auch hier wird das Umgehen von Browser- und Adblocker-Einschränkungen als Vorteil aufgeführt.
- „Google führt das serverseitige Tagging ein – eine gute Nachricht?“ von Nicolas Jaimes auf dem JDN. Der Blickwinkel des Artikels ist die Werbung, und daher wird das Umgehen der Browser-Schutzmaßnahmen als Vorteil aufgeführt (auch wenn Server-Side Tagging derzeit aufgrund des Mangels an Drittanbieter-Bibliotheken komplex zu implementieren bleibt).
Leider kann man davon ausgehen, dass viele Websites zusätzlich zu den Leistungs-, Sicherheits- und Kontrollgewinnen auch von diesen „Vorteilen“ profitieren werden. Auch für Datenschützer wäre die Unfähigkeit, Websites zu prüfen, ein großer Verlust. Wir hoffen, dass Browser und Adblocker Gegenmaßnahmen finden, damit Nutzer, die um ihre Privatsphäre besorgt sind, sich weiterhin wehren können.